Chapter 1 Why ‘EcoInformatics’?
Portions of the following introduction were adapted from Michener & Jones 2012, Trends in Ecology & Evolution ’Ecoinformatics: supporting ecology as a data-intensive science
Ecology is increasingly becoming a data-intensive science, relying on massive amounts of data collected by both remote-sensing platforms and sensor networks embedded in the environment. New observatory networks, such as the US National Ecological Observatory Network (NEON), provide research platforms that enable scientists to examine phenomena across diverse ecosystem types through access to thousands of sensors collecting diverse environmental observations. These networks spatially and temporaly overlap with a number of other networks and infrastructures ranging from remote sensing, to citizen science, and so on.
It has been argued that data-intensive science represents the fourth scientific paradigm following the empirical (i.e. description of natural phenomena), theoretical (e.g. modeling and generalization) and computational (e.g. simulation) scientific approaches, and comprises an approach for unifying theory, experimentation and simulation.
Ecologists increasingly address questions at broader scales that have both scientific and societal relevance. For example, the 40 top priorities for science that can inform conservation and management policy in the USA rely principally on a sound foundation of ecological research, and the ability to scale knowledge and inter-connect data.
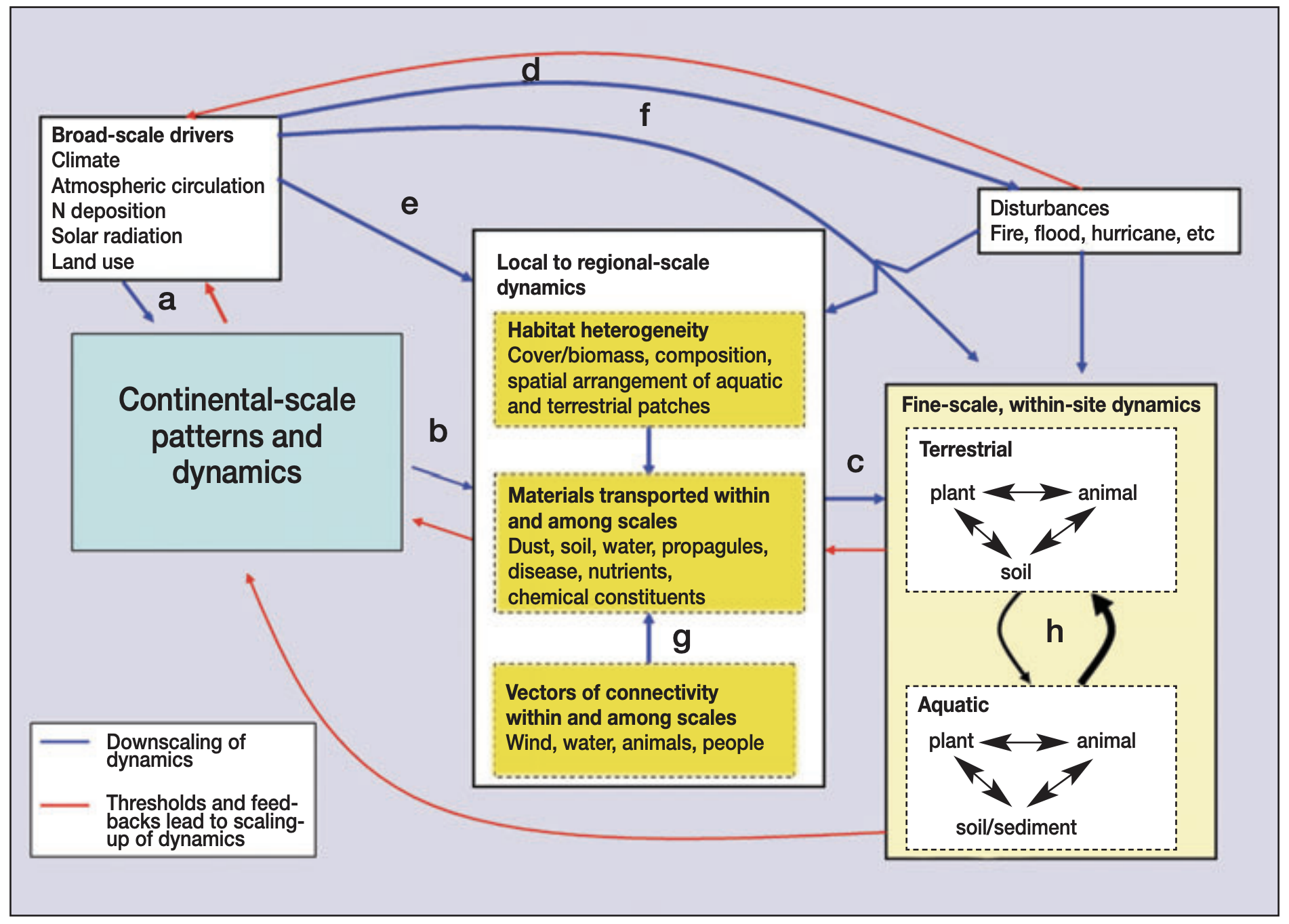
Continental-scale patterns and dynamics result from climate and people as broad-scale drivers interacting with finer-scale vectors that redistribute materials within and among linked terrestrial and aquatic systems. Climate and land-use change interact with patterns and processes at multiple, finer scales (blue arrows). (a) These drivers can influence broad-scale patterns directly, and these constraints may act to overwhelm heterogeneity and processes at (b) mesoscales and at (c) the finer scale of local sites. Broad-scale drivers can also exert an indirect impact on broad-scale patterns through their interactions with disturbances, including (d) the spread of invasive species, (e) pattern–process relationships at meso-scales, or (f) at finer scales within a site. Connectivity imparted by the transfer of materials occurs both at (g) the meso-scale and at (h) finer scales within sites where terrestrial and aquatic systems are connected. These dynamics at fine scales can propagate to influence larger spatial extents (red arrows). Feedbacks occur throughout the system. The term “drivers” refers to both forcing functions that are part of the system and to external drivers. Peters et al., 2008
Ecology is also affected by changes that are occurring throughout science as a whole.
In particular, scientists, professional societies and research sponsors are recognizing the value of data as a product of the scientific enterprise and placing increased emphasis on data stewardship, data sharing, openness and supporting study repeatability.
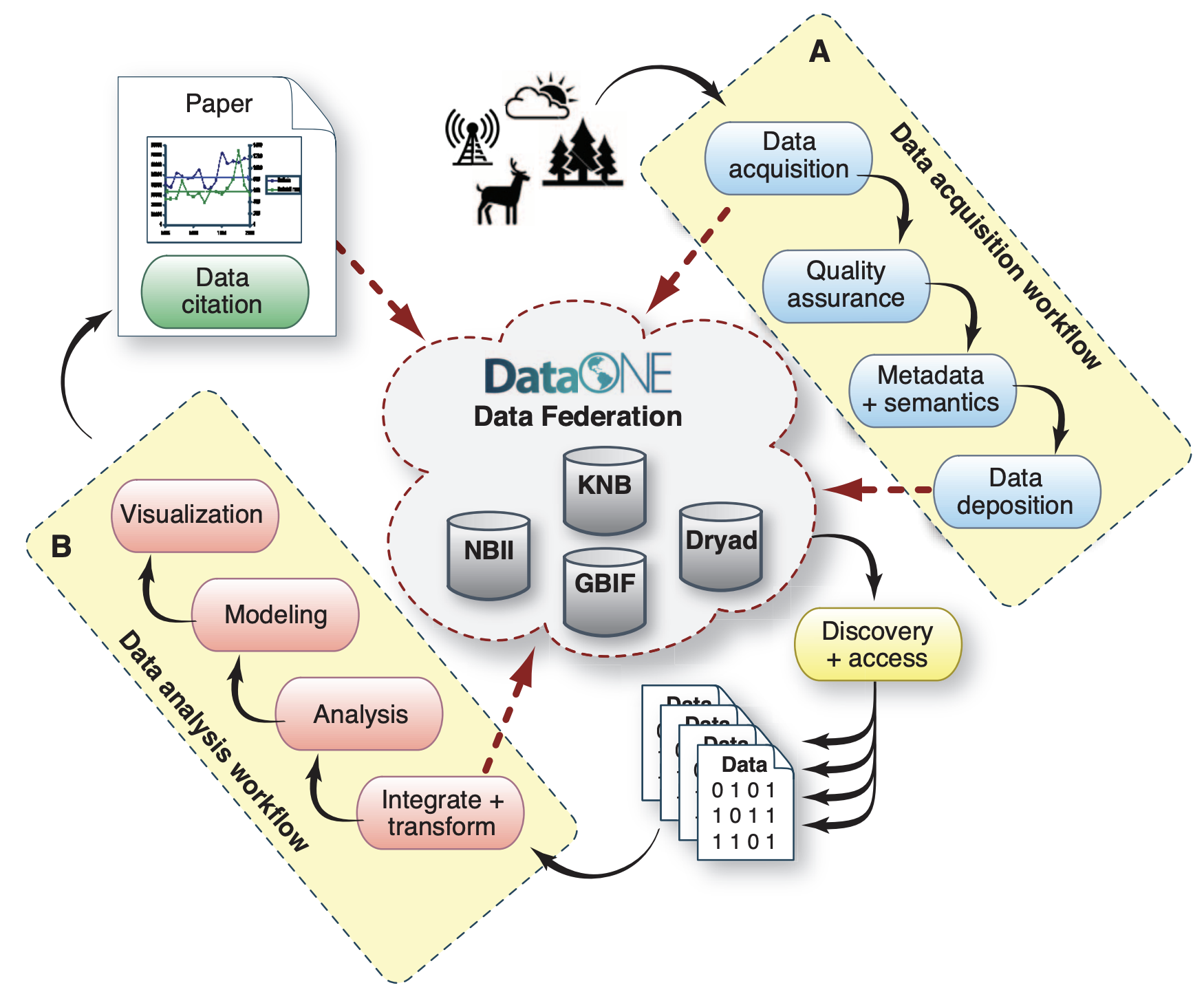
Data on ecological and environmental systems are (A) acquired, checked for quality, documented using an acquisition workflow, and then both the raw and derived data products are versioned and deposited in the DataONE federated data archive (red dashed arrows). Researchers discover and access data from the federation and then (B) integrate and process the data in an analysis workflow, resulting in derived data products, visualizations, and scholarly papers that are in turn archived in the data federation (red dashed arrows). Other researchers directly cite any of the versioned data, workflows, and visualizations that are archived in the DataONE federation. Richman et al., 2011
The changes that are occurring in ecology create challenges with respect to acquiring, managing and analyzing the large volumes of data that are collected by scientists worldwide.
One challenge that is particularly daunting lies in dealing with the scope of ecology and the enormous variability in scales that is encountered, spanning microbial community dynamics, communities of organisms inhabiting a single plant or square meter, and ecological processes occurring at the scale of the continent and biosphere. The diversity in scales studied and the ways in which studies are carried out results in large numbers of small, idiosyncratic data sets that accumulate from the thousands of scientists that collect relevant biological, ecological and environmental data.
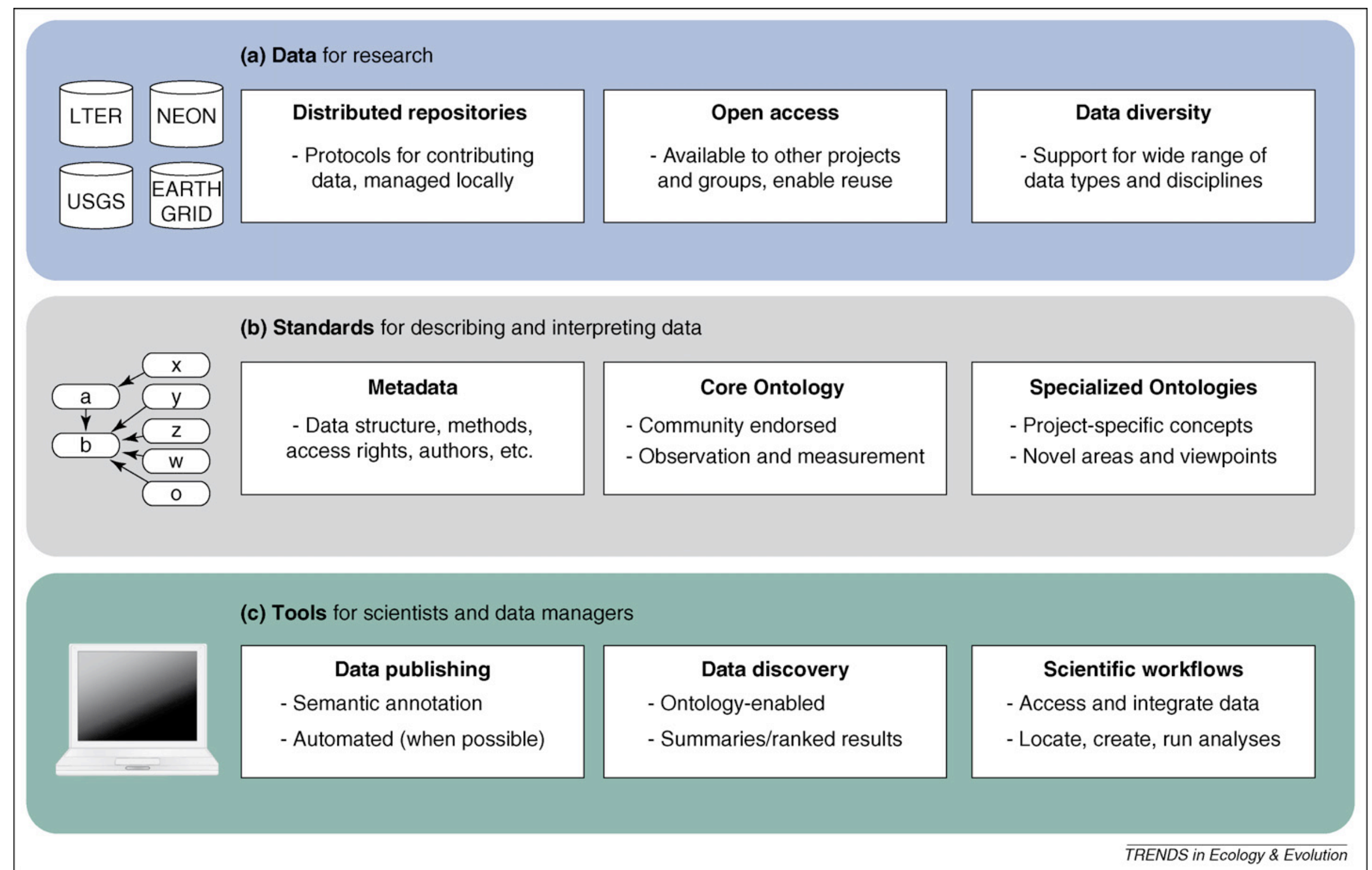
A proposed high-level architecture for ecological and environmental data management is shown consisting of three primary levels. Data stored within distributed data repositories (a) is mediated by standard metadata and ontologies (b) to power software tools used by scientists and data managers (c). Software applications use community-endorsed ontologies and metadata standards from the middle level to provide tools that are more effective for publishing, querying, integrating and analyzing data. Ontologies are separated into framework ontologies and domain-specific extensions, enabling contributions from multiple research groups, disciplines and individuals. Cross-disciplinary data are maintained in local repositories, but made accessible to the broader research community through distributed systems based on shared, open protocols (such as Metacat). Example repositories include the LTER network, National Ecological Observatory Network, United States Geographical Survey and SEEK’s EarthGrid. Madin et al. 2008,
Ecoinformatics is a framework that enables scientists to generate new knowledge through innovative tools and approaches for:
- discovering,
- managing,
- integrating,
- analyzing,
- visualizing,
- and preserving
relevant biological, environmental, and socioeconomic data and information. Many ecoinformatics solutions have been developed over the past decade, increasing scientists’ efficiency and supporting faster and easier data discovery, integration and analysis; however, many challenges remain, especially in relation to installing ecoinformatics practices into mainstream research and education.
And that, course participants, is why we are here.
1.1 The Framework of this Course
Over the duration of this course we will survey a wide array of observation platforms and networks and build hands-on experience with the framework of Ecoinformatics. For coherance we will cover the following overarching themes:
- Each network’s mission and design
- Each network’s spatial design
- e.g. opprtunistic vs. planned, citizen science vs. orbital sensors
- The types of data that stream from each network
- e.g. sensors, derived products, metadata
- How to access that data
- e.g. APIs, landing pages, r packages etc.
- Opportunities to interact with or contribute to each network
- e.g. RFP’s coming down the pipeline, internships, and post-doctoral scholar programs.
At the conclusion of each network’s section you will be asked to write a 1-page summary reviewing the above framework for each network, and highlight how it potentially aligns with your own research. These series of 1-page summaries will then culminate into a final presentation where you propose to derive your own data product for your own research touching upon multiple networks and accounting for differences in spatial footprints, frequency of observations, and important data cross-walks.
1.2 Final Course Project: Proposed Derived Data Product
For your final project, you will present a 4-6 minute IGNITE-style derived data product pitch, followed by 2-3 minutes of questions from your audience (which will include members from the infrastrures we’ve covered). Think of this project as your ‘sales pitch’ to the research infrastructure whose data you are using, and/or the scientific community as a whole. In the IGNITE theme of ‘Enlighten us but make it quick’, you will construct a series of slides that auto-advance every 30 seconds. Specific instructions for the content of each slide are below.
Ideally, this final presentation will feed upon a number of the ‘culmination write-ups’ you have conducted over the course of the semester. Ideally, this derived data product will utilize data from a number of sources, either covered within this course or external to it. Ideally, it will also convince your audience that your idea is novel, useful, and possible.
In order to complete this presentation, you will need to have worked with the various data products you propose, have an in-depth understanding of them, and their challenges, along with original, clean, high-level summary graphics. Further, giving an IGNITE-style presentation takes practice. IGNITE-style presentations are powerful, as they keep you moving forward, and give your audience a high-level understanding of your topic. We fully recommend rehearsing your presentation many times before giving it live and recording yourself to learn how you can improve.
Here’s an example (of an even faster) ignite talk from one of your book’s authors:
In your derived data product pitch you will cover these themes:
The need for the derived data that you are proposing to produce.
What data you will use to derive this product, including the justification for this exact data.
The processing pipeline for this product, along with estimates for a timeline.
Potential hurdles you will have to overcome.
How this product will serve the infrastructure and/or the scientific community.
Specific slide criteria are as follows:
Slide 1: Title, authors (including contacts at infrastructures covered if applicable)
Slide 2: Justification for the derived data product; the gap or need that it fills
Slides 3-x:
1 slide per data product used including:
The exact data product (e.g. NEON data product id and full title)
A 1 sentence summary of the data product and its justification for this purpose
An original, clean, polished high-level plot, gif or .mp4 of the data
Slide x + 1: A high-level workflow diagram of the processing pipeline E.g.: Original data and how you pull it in (API, r-package etc)
Filtering process using QA/QC or metadata
Orthorectification in time or space
Example generated using draw.io:
.png)
Slide x + 2: A clean plot of all of the data you mentioned together, and/or the derived data product itself with a 1 sentence summary
Example:
Slide x+3: Summary: Circle back on how this derived data product serves your research, the infrastructure, and the wider science community (no more than 10 words, suggestion: graphics or bullet points)
Slide x + 4: Data citations for all data used in proposed derived data product
An example slide deck with specific ideas can be found here
The rubric for your final presentation grade is as follows:
Presentation meets all requirements and criteria: 60%
Aesthetics and craft of presentation: 10%
Live presentation of materials: 30%